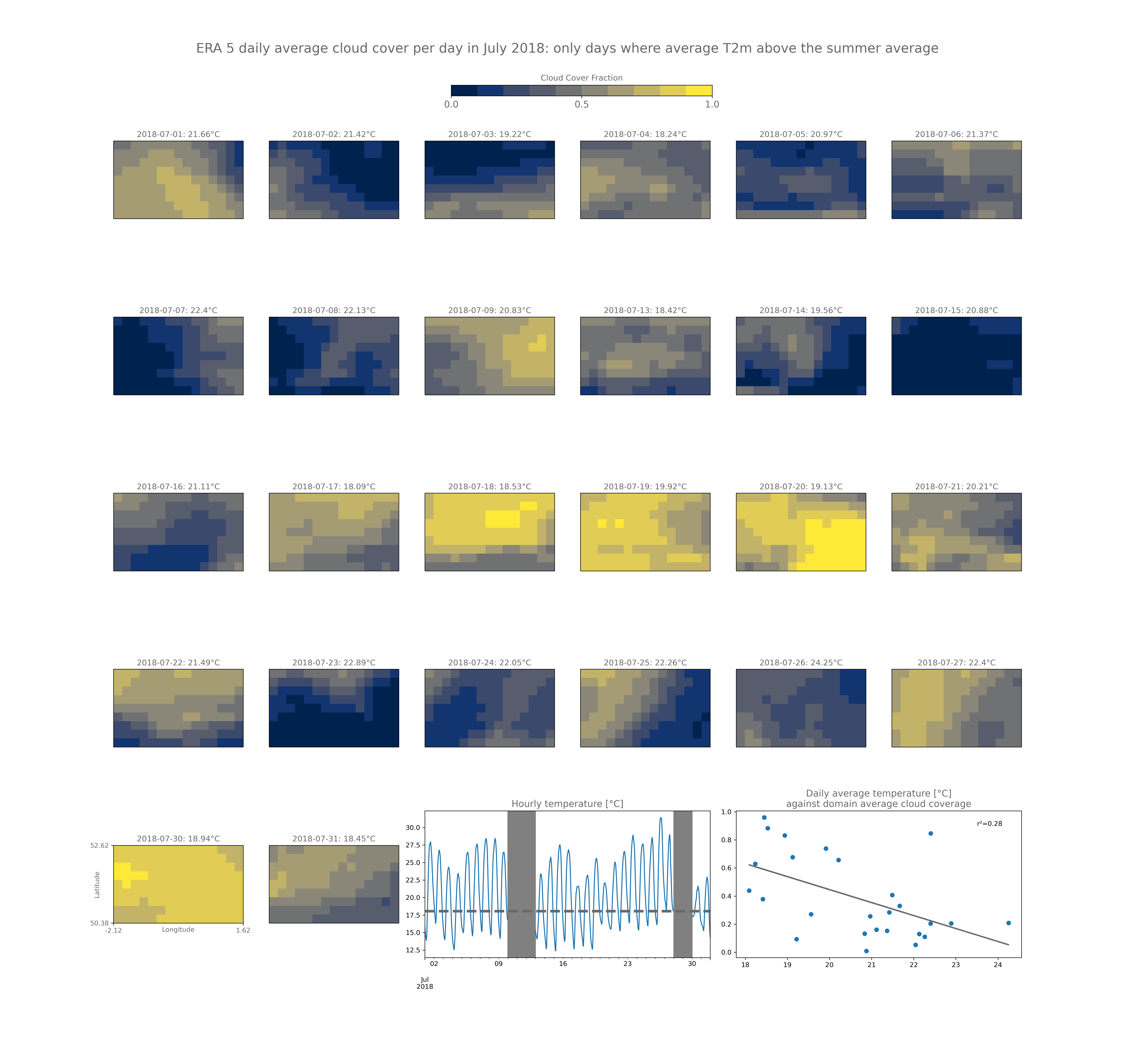
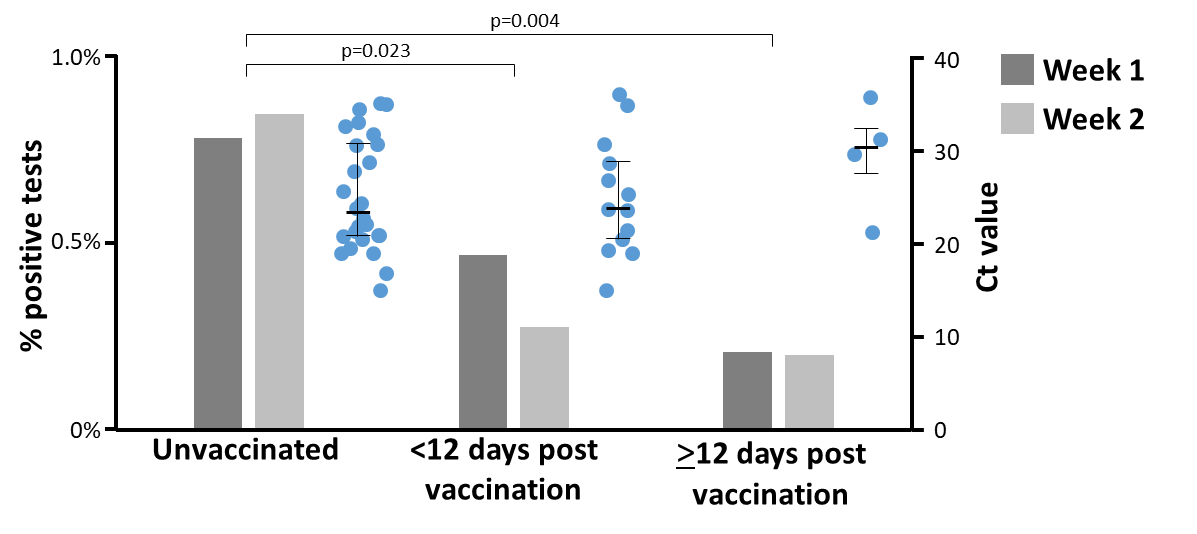
Nick K. Jones1,2*, Lucy Rivett1,2*, Chris Workman3, Mark Ferris3, Ashley Shaw1, Cambridge COVID-19 Collaboration1,4, Paul J. Lehner1,4, Rob Howes5, Giles Wright3, Nicholas J. Matheson1,4,6¶, Michael P. Weekes1,7¶1 Cambridge University NHS Hospitals Foundation Trust, Cambridge, UK2 Clinical Microbiology & Public Health Laboratory, Public Health England, Cambridge, UK3 Occupational Health and Wellbeing, Cambridge Biomedical Campus, Cambridge, UK4 Cambridge Institute of Therapeutic Immunology & Infectious Disease, University of Cambridge, Cambridge, UK5 Cambridge COVID-19 Testing Centre and AstraZeneca, Anne Mclaren Building, Cambridge, UK6 NHS Blood and Transplant, Cambridge, UK7 Cambridge Institute for Medical Research, University of Cambridge, Cambridge, UK*Joint first authorship¶Joint last authorshipCorrespondence: [email protected] UK has initiated mass COVID-19 immunisation, with healthcare workers (HCWs) given early priority because of the potential for workplace exposure and risk of onward transmission to patients. The UK’s Joint Committee on Vaccination and Immunisation has recommended maximising the number of people vaccinated with first doses at the expense of early booster vaccinations, based on single dose efficacy against symptomatic COVID-19 disease.1-3At the time of writing, three COVID-19 vaccines have been granted emergency use authorisation in the UK, including the BNT162b2 mRNA COVID-19 vaccine (Pfizer-BioNTech). A vital outstanding question is whether this vaccine prevents or promotes asymptomatic SARS-CoV-2 infection, rather than symptomatic COVID-19 disease, because sub-clinical infection following vaccination could continue to drive transmission. This is especially important because many UK HCWs have received this vaccine, and nosocomial COVID-19 infection has been a persistent problem.Through the implementation of a 24 h-turnaround PCR-based comprehensive HCW screening programme at Cambridge University Hospitals NHS Foundation Trust (CUHNFT), we previously demonstrated the frequent presence of pauci- and asymptomatic infection amongst HCWs during the UK’s first wave of the COVID-19 pandemic.4 Here, we evaluate the effect of first-dose BNT162b2 vaccination on test positivity rates and cycle threshold (Ct) values in the asymptomatic arm of our programme, which now offers weekly screening to all staff.Vaccination of HCWs at CUHNFT began on 8th December 2020, with mass vaccination from 8th January 2021. Here, we analyse data from the two weeks spanning 18thto 31st January 2021, during which: (a) the prevalence of COVID-19 amongst HCWs remained approximately constant; and (b) we screened comparable numbers of vaccinated and unvaccinated HCWs. Over this period, 4,408 (week 1) and 4,411 (week 2) PCR tests were performed from individuals reporting well to work. We stratified HCWs <12 days or > 12 days post-vaccination because this was the point at which protection against symptomatic infection began to appear in phase III clinical trial.226/3,252 (0·80%) tests from unvaccinated HCWs were positive (Ct<36), compared to 13/3,535 (0·37%) from HCWs <12 days post-vaccination and 4/1,989 (0·20%) tests from HCWs ≥12 days post-vaccination (p=0·023 and p=0·004, respectively; Fisher’s exact test, Figure). This suggests a four-fold decrease in the risk of asymptomatic SARS-CoV-2 infection amongst HCWs ≥12 days post-vaccination, compared to unvaccinated HCWs, with an intermediate effect amongst HCWs <12 days post-vaccination.A marked reduction in infections was also seen when analyses were repeated with: (a) inclusion of HCWs testing positive through both the symptomatic and asymptomatic arms of the programme (56/3,282 (1·71%) unvaccinated vs 8/1,997 (0·40%) ≥12 days post-vaccination, 4·3-fold reduction, p=0·00001); (b) inclusion of PCR tests which were positive at the limit of detection (Ct>36, 42/3,268 (1·29%) vs 15/2,000 (0·75%), 1·7-fold reduction, p=0·075); and (c) extension of the period of analysis to include six weeks from December 28th to February 7th 2021 (113/14,083 (0·80%) vs 5/4,872 (0·10%), 7·8-fold reduction, p=1x10-9). In addition, the median Ct value of positive tests showed a non-significant trend towards increase between unvaccinated HCWs and HCWs > 12 days post-vaccination (23·3 to 30·3, Figure), suggesting that samples from vaccinated individuals had lower viral loads.We therefore provide real-world evidence for a high level of protection against asymptomatic SARS-CoV-2 infection after a single dose of BNT162b2 vaccine, at a time of predominant transmission of the UK COVID-19 variant of concern 202012/01 (lineage B.1.1.7), and amongst a population with a relatively low frequency of prior infection (7.2% antibody positive).5This work was funded by a Wellcome Senior Clinical Research Fellowship to MPW (108070/Z/15/Z), a Wellcome Principal Research Fellowship to PJL (210688/Z/18/Z), and an MRC Clinician Scientist Fellowship (MR/P008801/1) and NHSBT workpackage (WPA15-02) to NJM. Funding was also received from Addenbrooke’s Charitable Trust and the Cambridge Biomedical Research Centre. We also acknowledge contributions from all staff at CUHNFT Occupational Health and Wellbeing and the Cambridge COVID-19 Testing Centre.


/screenshot (1).png?1566398100)